
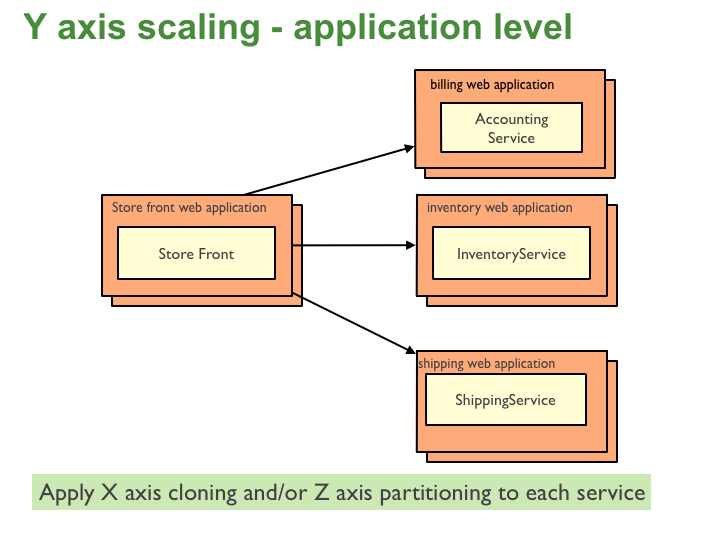
There have been alot of discussions on
Microservices lately. Alot of concentration has been around the services
themselves. But what about the Data that these Services need and use?
Should Data be tightly coupled to the microservice? Should there
be abstraction between the service and the data? In this blog we will
touch on Micro Data Services and how I think they can be created.
A microservice is a software architecture style,
a form of application development, in which applications are built and composed
as a suite of services. The services are small, independent, self
contained, independently deployable and scalable. They are highly
decoupled and focus on a small task or capability. So a formal definition:
Microservices is an architectural approach, that emphasizes the functional decomposition of applications into single-purpose, loosely coupled services managed by cross-functional teams, for delivering and maintaining complex software systems with the velocity and quality required by today’s digital business.
One of the characteristics of microservices,
described by Martin
Fowler, in his microservices article,
is described as Decentralized Data Management. He describes this as
letting each service manage its own database. Either different instances
of the same database technology or entirely different database systems.
As he indicated this is an approach called Polyglot Persistence.
In the context of the database, this is referring to services using a mix of
databases to take advantage of the fact that different databases are suitable
for different types of programs. Of course there maybe already existing silos
or monolith databases that the microservices need to use.
So first let's talk about going from Monolith to
Microservices visually and then let's talk about how Data Virtualization can
help Enterprises move to microservices.
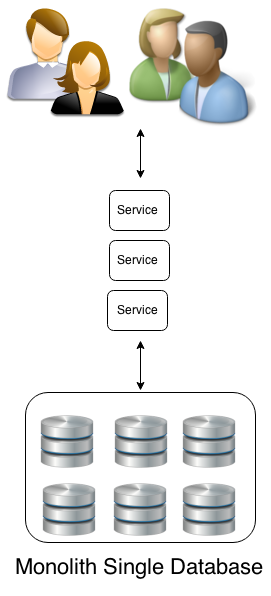
The monolith application
is single-tiered and the user interface and data access code are put in a
single program in a single platform. Usually a monolith describes main
frame type applications with tight coupling of the components instead of reuse
modularity. There are several disadvantages to using the monolith
approach:
- Less
iteration due to large code base and complex integration points with many
dependencies
- Maintenance
of the large code base
- Code
quality can be poor with the large code base

The
Microservice architecture encompasses the application components together into
the small independent service including the data access. I wanted to highlight some of the advantages
to using microservices:
·
Microservice architecture gives developers the freedom to
independently develop and deploy services
·
A microservice can be developed by a fairly small team
·
Code for different services can be written in different languages
(though many practitioners discourage it)
·
Easy integration and automatic deployment (using open-source
continuous integration tools such as Jenkins, Hudson, etc.)
·
Easy to understand and modify for developers, thus can help a
new team member become productive quickly
·
The developers can make use of the latest technologies
·
The code is organized around business capabilities
·
Starts the web container more quickly, so the deployment is also
faster
·
When change is required in a certain part of the application,
only the related service can be modified and redeployed—no need to modify and
redeploy the entire application
·
Better fault isolation: if one microservice fails, the other
will continue to work (although one problematic area of a monolith application
can jeopardize the entire system)
·
Easy to scale and integrate with third-party services
·
No long-term commitment to technology stack
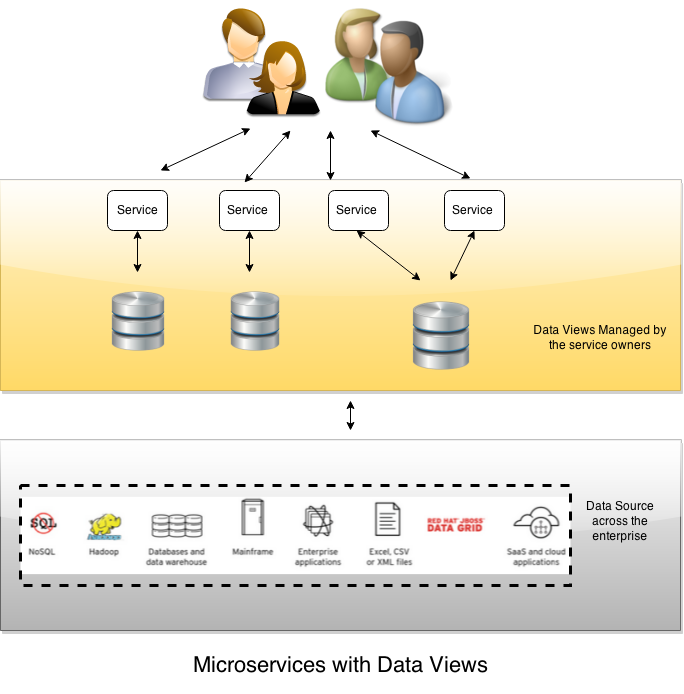
Now let’s move toward the
data discussion with Microservices. How
can I create a Micro Data Service so the microservice has access to the data it
needs and only the data it needs? That
is where we can pull in JBoss Data Virtualization to allow easy migration and
adoption of microservices. As seen in the diagram below we have a lot of
different data sources that microservices may need. So we can use Data Virtualization to add
Micro Data Services for each of the microservices. We can also add Security such as row level
security and column masking to the Virtual Database (VDB). The VDB can be created for each microservice
or we can create Multiple Micro Views in the VDBs. What are the Benefits to using Data
Virtualization for Micro Data Services?
·
Connect to many Datasources
·
Create VDBs and Views according to capabilities
·
Expose the VDBs through
different standards (ODBC, JDBC, OData, REST, SOAP) for the microservices
·
Ability to place your Micro Data Service in the xPaaS on
Openshift
·
Create the access levels based on roles for fine grained access
·
Keep your data stores as they are with new DV views and Migrate to
new sources easily with DV
·
Provide the same data services used in the microservices to
Business Intelligence Analytic tools
Now
that you see the advantages and I have peaked your curiosity, check out the
Videos, Documentation and Downloads to start you first Data Service for use
with your Microservices:
- Review the Documentation: http://www.jboss.org/products/datavirt/resources/
- Download the product: http://www.jboss.org/products/datavirt/download/
- Watch the getting started videos: http://www.jboss.org/products/datavirt/get-started/#!project=datavirt
References: