

This is the second in our Data Virtualization Primer Basics Series. I cover the concepts in the presentation below which are also at http://teiid.jboss.org/basics/. We will also highlight some of the concepts in this article.
We have some main concepts that we should highlight which are:
- Source Models
- View Models
- Translators
- Resource Adaptors
- Virtual Databases
- Modeling and Execution Environments
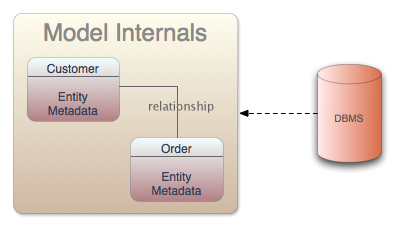
Source Models represent the structure and characteristics of physical data sources and the source model must be associated with a translator and a resource adaptor. View Models represent the structure and characteristics you want to expose to your consumers. These view models are used to define a layer of abstraction above the physical layer. This enables information to be presented to consumers in business terms rather than as it is physically stored. The views are defined using transformations between models. The business views can be in a variety of forms: relational, XML or Web Services.
A Translator provides a abstraction layer between the DV query engine and physical data source, that knows how to convert DV issued query commands into source specific commands and execute them using the Resource Adaptor. DV provides pre-built translators like Oracle, DB2, MySQL, Postgres, etc. The resource adaptor provides the connectivity to the physical data source. This provides the way to natively issue commands and gather results. A resource adaptor can be a Relational data source, web service, text file, main frame connection, etc.
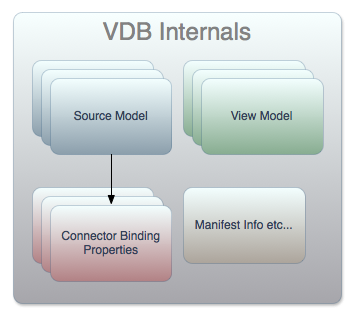
The two main high level components are the Modeling and Execution Environments. The Modeling Environment is used to define the abstraction layers. The Execution Environment is used to actualize the abstract structures from the underlying data, and expose them through standard APIs. The DV query engine is a required part of the execution environment, to optimally federate data from multiple disparate sources.
Now that we highlighted the concepts, the last topic to cover is why the data abstraction, the data services, are good for SOA and Microservices. Below are some of the reasons why the data services are important in these architectures:
- Expose all data through a single uniform interface
- Provide a single point of access to all business services in the system
- Expose data using the same paradigm as business services - as "data services"
- Expose legacy data sources as data services
- Provide a uniform means of exposing/accessing metadata
- Provide a searchable interface to data and metadata
- Expose data relationships and semantics
- Provide uniform access controls to information
Stayed tuned for the next Data Virtualization Primer topic!
Series 1 - The Basics
- Introduction
- The Concepts (SOAs, Data Services, Connectors, Models, VDBs)
- Architecture
- On Premise Server Installation
- JBDS and Integration Stack Installation
- WebUI Installation
- Teiid Designer - Using simple CSV/XML Datasources (Teiid Project, Perspective, Federation, VDB)
- JBoss Management Console
- The WebUI
- The Dashboard Builder
- OData with VDB
- JDBC Client
- ODBC Client
- DV on Openshift
- DV on Containers (Docker)