|
| https://www.facebook.com/hadoopers |
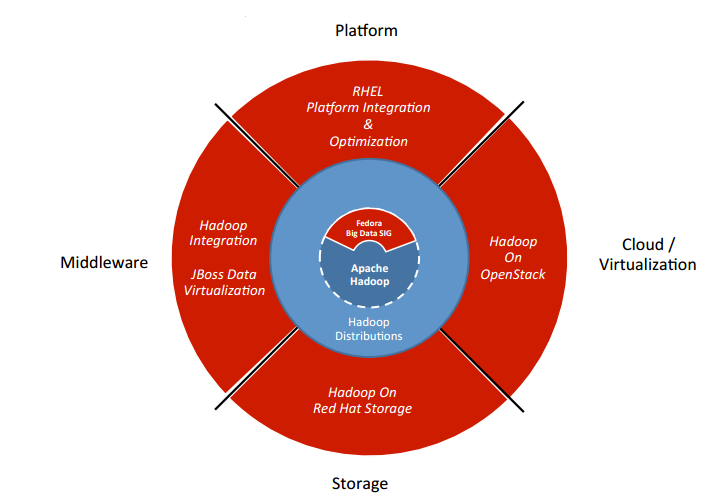
In some of our Articles and Demos we have examples of JBoss Data Virtualization (Teiid) using Hadoop as a Data Source through Hive. When creating examples of Data Virtualization with Hadoop Environments such as Hortonworks Data Platform, Cloudera Quickstart, etc. there are alot of open source projects included. I wanted to highlight some of those so that you have an overview of the Hadoop Ecosystem. You can find the information below as well as more projects detail in the ecosystem from the hadoop ecosystem table.
Map Reduce - MapReduce is a programming model for processing large data sets with a parallel, distributed algorithm on a cluster. Apache MapReduce was derived from Google MapReduce: Simplified Data Processing on Large Clusters paper. The current Apache MapReduce version is built over Apache YARN Framework. YARN stands for “Yet-Another-Resource-Negotiator”. It is a new framework that facilitates writing arbitrary distributed processing frameworks and applications. YARN’s execution model is more generic than the earlier MapReduce implementation. YARN can run applications that do not follow the MapReduce model, unlike the original Apache Hadoop MapReduce (also called MR1). Hadoop YARN is an attempt to take Apache Hadoop beyond MapReduce for data-processing.
HDFS - The Hadoop Distributed File System (HDFS) offers a way to store large files across multiple machines. Hadoop and HDFS was derived from Google File System (GFS) paper. Prior to Hadoop 2.0.0, the NameNode was a single point of failure (SPOF) in an HDFS cluster. With Zookeeper the HDFS High Availability feature addresses this problem by providing the option of running two redundant NameNodes in the same cluster in an Active/Passive configuration with a hot standby.
HBase - Google BigTable Inspired. Non-relational distributed database. Ramdom, real-time r/w operations in column-oriented very large tables (BDDB: Big Data Data Base). It’s the backing system for MR jobs outputs. It’s the Hadoop database. It’s for backing Hadoop MapReduce jobs with Apache HBase tables.
Hive - Data Warehouse infrastructure developed by Facebook. Data summarization, query, and analysis. It’s provides SQL-like language (not SQL92 compliant): HiveQL.
Pig - Pig provides an engine for executing data flows in parallel on Hadoop. It includes a language, Pig Latin, for expressing these data flows. Pig Latin includes operators for many of the traditional data operations (join, sort, filter, etc.), as well as the ability for users to develop their own functions for reading, processing, and writing data. Pig runs on Hadoop. It makes use of both the Hadoop Distributed File System, HDFS, and Hadoop’s processing system, MapReduce. Pig uses MapReduce to execute all of its data processing. It compiles the Pig Latin scripts that users write into a series of one or more MapReduce jobs that it then executes. Pig Latin looks different from many of the programming languages you have seen. There are no if statements or for loops in Pig Latin. This is because traditional procedural and object-oriented programming languages describe control flow, and data flow is a side effect of the program. Pig Latin instead focuses on data flow.
Zookeeper - It’s a coordination service that gives you the tools you need to write correct distributed applications. ZooKeeper was developed at Yahoo! Research. Several Hadoop projects are already using ZooKeeper to coordinate the cluster and provide highly-available distributed services. Perhaps most famous of those are Apache HBase, Storm, Kafka. ZooKeeper is an application library with two principal implementations of the APIs—Java and C—and a service component implemented in Java that runs on an ensemble of dedicated servers. Zookeeper is for building distributed systems, simplifies the development process, making it more agile and enabling more robust implementations. Back in 2006, Google published a paper on "Chubby", a distributed lock service which gained wide adoption within their data centers. Zookeeper, not surprisingly, is a close clone of Chubby designed to fulfill many of the same roles for HDFS and other Hadoop infrastructure.
Mahout - Machine learning library and math library, on top of MapReduce.
Also, you can visit the Big Data Insights Page to learn more about Red Hat Products in relation to the Hadoop Ecosystem.